
Mentre il mercato dell’intelligenza artificiale continua a riempirsi di prodotti che promettono miracoli e punteggi record, il motore di ricerca Kagi ha deciso di percorrere una strada diversa con i suoi nuovi assistenti di ricerca. E lo fa con un approccio che suona quasi controcorrente: hanno ottenuto il miglior risultato su uno dei benchmark più noti del settore, ma hanno scelto deliberatamente di non inseguire ulteriori miglioramenti su quel fronte.
Due strumenti, due filosofie d’uso
Il motore di ricerca indipendente ha presentato ufficialmente Quick Assistant e Research Assistant (quest’ultimo conosciuto come “Ki” durante la fase beta), due strumenti pensati per scenari d’uso completamente diversi.
Il Quick Assistant punta tutto sulla velocità: risponde in meno di cinque secondi con informazioni dirette e concise. È disponibile per tutti gli utenti Kagi e ha un impatto trascurabile sui consumi del piano. Perfetto quando hai bisogno di una risposta rapida senza troppi fronzoli.
Il Research Assistant, invece, è tutt’altra storia. Richiede oltre 20 secondi per completare la ricerca, consuma più risorse del piano (viene applicata la politica di fair use), ed è riservato agli abbonati Ultimate. In compenso, va in profondità: esegue ricerche multiple in parallelo, anche in lingue diverse se necessario, e sintetizza i risultati in risposte strutturate e verificabili.
Accessibili direttamente dalla barra di ricerca
Una delle scelte più interessanti riguarda l’integrazione. Non servono app dedicate o interfacce separate: basta usare i “bang” direttamente nella barra di ricerca di Kagi.
!quickrichiama il Quick Assistant!researchattiva il Research Assistant- Il classico
?mantiene la funzione di risposta rapida standard
Ad esempio, digitando “Migliore squadra di calcio attuale !research” si attiva l’assistente approfondito. Semplice e immediato.
La questione dei benchmark (e perché Kagi ha smesso di corrergli dietro)
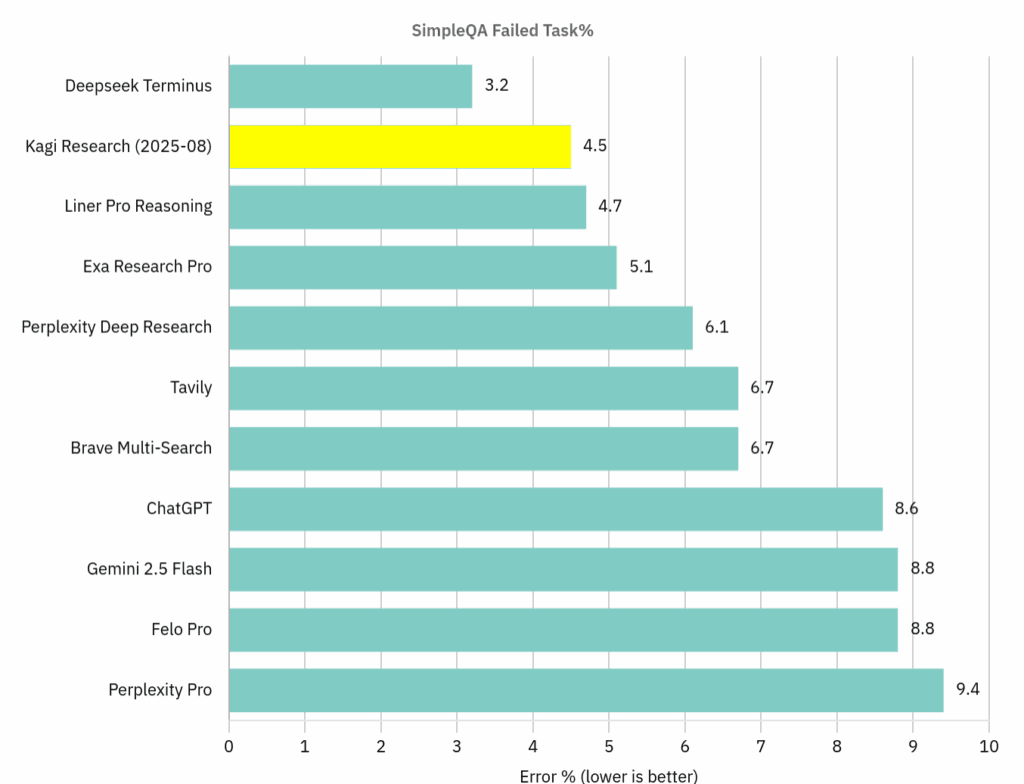
Qui le cose si fanno interessanti. Nell’agosto 2025, il Research Assistant di Kagi ha ottenuto un punteggio del 95,5% su SimpleQA, un benchmark creato per misurare la capacità dei modelli di richiamare informazioni fattuali senza allucinare. Era, per quanto ne sapevano loro, il punteggio più alto mai registrato.
La reazione? Non hanno festeggiato con comunicati stampa trionfalistici. Anzi, hanno dichiarato pubblicamente di non voler migliorare ulteriormente quel punteggio. Il motivo è semplice quanto sensato: ottimizzare per un singolo benchmark significa modellare il prodotto su quel dataset specifico, con il rischio di peggiorare le prestazioni reali per gli utenti.
Cosa hanno scoperto analizzando SimpleQA
Scavando nei casi in cui il loro assistente falliva, il team di Kagi ha trovato situazioni curiose:
- Fonti ufficiali che contraddicono la risposta “corretta” del benchmark (come i dati sulle montagne russe “Rattler” dove il sito ufficiale Six Flags riporta 81 gradi mentre il benchmark considera corretti i 61 gradi di Coasterpedia)
- Informazioni trovabili solo su Wikipedia in spagnolo o su pagine archiviate su Internet Archive (e no, non vogliono addestrare i loro modelli a martellare l’Archive con crawler aggressivi)
- Domande che riflettono inevitabilmente i bias personali dei ricercatori che hanno creato il benchmark
L’umano al centro, non il modello
La filosofia di Kagi sugli assistenti IA è chiara: gli LLM sono strumenti potenti ma tendono a “sparare stronzate” (bullshit, testualmente). La soluzione non è fingere che questo problema non esista, ma costruire prodotti che ne tengano conto.
Ogni risposta del Research Assistant include citazioni verificabili. Non solo: accanto a ogni fonte viene indicato quanto quella fonte è rilevante per la risposta finale. L’obiettivo non è sostituire il processo di ricerca umano, ma accelerarlo fornendo un punto di partenza solido che inviti l’utente ad approfondire.
È una differenza sottile ma fondamentale rispetto agli strumenti di “deep research” che producono lunghi report. Report dettagliati vanno bene per alcune situazioni, ma per la maggior parte delle domande non sono il formato migliore. Anche quando la domanda richiede parecchia ricerca.
Un dettaglio tecnico che fa la differenza
Durante i test su SimpleQA, il team di Kagi ha notato qualcosa di interessante: lo stesso modello linguistico otteneva risultati migliori quando usava Kagi Search come backend invece di Google o Bing. Non perché Kagi trovi informazioni magiche che gli altri non hanno, ma perché i risultati contengono meno rumore.
Meno spam, meno contenuti irrilevanti, meno inquinamento del contesto che confonde il modello. In pratica, Kagi filtra meglio e questo fa la differenza quando un LLM deve elaborare le informazioni.
Oltre la ricerca web
I due assistenti non si limitano a cercare su internet. Possono eseguire codice per verificare calcoli, generare immagini, interrogare API specifiche come Wolfram Alpha, cercare notizie recenti o informazioni geolocalizzate. E lo fanno in modo naturale, come parte del processo di risposta, senza che l’utente debba specificare quale strumento usare.
Una scelta di campo
In un mercato dove ogni giorno esce un nuovo prodotto IA che promette di rivoluzionare tutto, Kagi ha fatto una scelta precisa: costruire strumenti utili senza forzare l’intelligenza artificiale dove non serve. Il Research Assistant esiste perché loro lo trovano utile. Se lo trovi utile anche tu, bene. Altrimenti, nessuno te lo impone.
È un approccio quasi anacronistico, in senso positivo. E forse è proprio quello di cui c’è bisogno in questo momento storico dell’IA.
 Mastodon
Mastodon
 Telegram
Telegram
 Bluesky
Bluesky
Lascia un commento